The equivalence test in analytical similarity assessment uses a margin of 1.5 times of the standard deviation of a reference product. In the current practice, the standard deviation, estimated from study data, is considered as a fixed constantin the margin [1]. The impact of such a practice leads to the inflation of type I error rate and the reduction of power as previous studies showed [2]. In order to accommodate the fact that the margin is a parameter and improve the efficiency when the numbers of lots for both products are small. Chen, et al. [3] proposed to use Wald test with Constrained Maximum Likelihood Estimate (CMLE) of the standard error, resulting in the type I error rate is below the nominal value. In this paper, we further improve the Wald test with CMLE standard error by replacing the maximum likelihood estimate of reference standard deviation in the margin with the sample estimate. For small numbers of lots for both products, this estimate replacement leads to further improvement of type I error rate and power over the tests proposed in Chen, et al. [3]. In addition, to satisfy the criteria that the power is greater than 85% with the number of product lots being ten and equal product variability, we propose to use a margin of 1.7 times of the standard deviation of a reference product.
Equivalence tests, Wald tests, Constrained maximum likelihood estimate
Two one-sided hypothesis tests with a parameter margin that is a function of the variability of the reference product have been applied to equivalence assessments in several pharmaceutical areas [3-5]. The two one-sided hypotheses can be written as follows.
where and are the population means of the test product and the reference product, respectively, is the Standard Deviation (SD) of the reference product and is the pre-specified constant.
Hypotheses in (1) has been proposed in various applications. Shen and Xu [5] proposed in designs of method transfer studies for biotechnology products to compare means between the sending laboratory and the receiving laboratory. In their study, and represent the population mean of the measurements under normality distributions obtained at the receiving laboratory and the sending laboratory, respectively, and represents the population SD of the measurements obtained at the sending laboratory. For the evaluation of the analytical similarity between a test product and the reference product, Tsong, et al. [4] proposed to assess the equivalence in means for a selected Critical Quality Attribute (CQA) by testing the hypotheses in (1) with . The current practice is just substituting the sample SD of the Reference Product in the margin as if it is a known value although is unknown and needed to be estimated from the study data [1]. Hence, under the normality assumption, the current analysis using t statistics results in inflating type I error rate and reducing power as pointed out by Dong, et al. [2] and Burdick, et al. [6].
To reduce the deficiency, one alternative approach is considering as a parameter and then applying the Wald-type statistic to hypotheses in (1). Chen, et al. [3] pointed out that the Wald test led to type I error rate seriously lower than the nominal significance level and power smaller than the target power value when the numbers of product lots are small. Chen, et al. [3] proposed a modified Wald test by using the Constrained Maximum Likelihood Estimate (CMLE)-method. With the Constrained Maximum Likelihood Estimate, the standard error was estimated using Maximum Likelihood Estimator (MLE) restricted to the null hypotheses in (1). Based on simulations, this CMLE-method led to slightly increase type I error rate but still less than the nominal significance value when the numbers of product lots are smaller than 20. Later, Burdick, et al. [6] and Dong, et al. [2] proposed to use Generalized Pivotal Quantity (GPQ) [7] to better control the type I error rate inflation and improve the power performance. Simulations showed that the type I error rate for the GPQ method is below the nominal significance value except for some small-lot-number scenarios in which the simulated type I error rate can be inflated to around 5.3%. In this paper, we further improve the Wald test with CMLE standard error [3] by replacing the MLE of in the equivalence margin with the sample estimate to further increase type I error rate while still below the nominal significance level and increase power when the numbers of product lots are small.
This paper is structured as follows. In Section 2, we consider three methods to construct Wald tests with CMLEs for standard error estimation. In Section 3, we describe the simulation plan and evaluate type I error rate and power performance of these three Wald tests. We provide an example to apply our proposed method to a simulated dataset and compare the proposed method with the current practice in Section 4. We present the discussion and conclusions in Section 5. For the simplicity of discussion, we consider only normally distributed measurements.
We first derive the proposed improved Wald test statistic and the other two estimators and then propose improved Wald test statistic with size adjustment to mitigate the imbalance between the numbers of the reference product lots and the test product lots.
To achieve at least 85% power when the mean difference is 1/8 of the reference standard deviation and the numbers of the reference product lots and the test product lots equal to ten, with equal variability, the current practice led f to be 1.5 [1]. More details are described in Tsong, et al. [4].
In this paper, we propose and for estimating the parameters and , respectively. denote the MLE for the mean of the test product, the MLE for the mean of the reference product and the sample estimator for the SD of the reference product, respectively. When is distributed from Normal and is distributed from Normal
where and denote the numbers of test lots and reference lots, respectively . is the variance of the test product. Then, we compare the proposed estimators to the other two sets of estimators: The unbiased version of the proposed estimators and the CMLEs proposed by Chen, et al. [3]. To correct the bias of the proposed estimators, we define that and . As described in Ahn and Fessler [8], k is the bias correction factor of the SD of the reference product such that
where is the gamma function defined as , y is a positive number. For the CMLE-method proposed by Chen, et al. [3], the estimators are and . denotes the MLE of the SD of the reference product, which is defined as . Under either of the null hypotheses in (1), none of the three estimators has an exact distribution when we consider the unknown as a parameter. Therefore, we resort to asymptotic standard normal approximation for Wald test statistics.
The method of obtaining CMLEs for the variances is detailed in Chen, et al. [3]. We briefly describe the approach of calculating CMLEs. Considering the log-likelihood function under either of the constraint in the two null hypotheses in (1), we first derive the MLEs for under the constraint in . More specifically, the log-likelihood function is given by
Then, the CMLE for is given by , and the CMLE of is estimated numerically by Gibbs sampling. In the simulation study described in next Section, the estimators are obtained using R function and the code derived from (2) is attached in the Appendix 1. By substituting , the CMLE for is given by . The CMLE under the constraint in can be derived in the similar way.
Three Wald tests for testing the null hypothesis is constructed based on three different estimators . As described in Ahn and Fessler [8], the standard error of can be estimated by , where is the variance of the chi distribution with degrees of freedom. Thus, in our proposed Modified Wald test with CMLE (MWCMLE), the standard error is given by . Then can be estimated by where is CMLE of variance .
The quantity can be used for testing . Plugging MLE for the test product mean, MLE for the reference product mean, sample estimator for the SD of the reference product and CMLE , we have the following test statistic.MWCMLE:
Following a similar derivation, the test statistic for the other two estimators, the unbiased version of the MWCMLE and the CMLE-method, can be derived as follows.
Unbiased Modified Wald test with CMLE (UMWCMLE):
Wald test with CMLE (CMLE-method in Chen, et al. 2017) [3]:
Similarly, we derive three Wald tests for testing based on the corresponding quantity as follows.
MWCMLE:
UMWCMLE:
CMLE-method:
Under the null hypothesis, each test follows an asymptotically standard normal distribution. The null hypotheses in (1) is rejected if for t = 1, 2, 3 at significance level , where is the 100pth percentile of the standard normal distribution. With this criterion, we evaluated type I error rate and power for each test in Section 3.
Because the analytical similarity study is an un-blinded study, the number of reference lots can be much larger than the number of test lots. However, we do not want the information from the reference product to dominate the equivalence testing. Thus, Dong, et al. [9] proposed to compute the following confidence interval with the number of the adjusted reference lots and adjusted degrees of freedom when the ratio of the number of reference lots to the number of test lots is great than 1.5.
Here denote sample mean difference between the test and the reference products, sample variance of the reference product, and sample variance of the test product, respectively. The number of adjusted reference lots, , is equal to min . . denote the number of test lots and the number of reference lots, respectively. The is quantile of the t-distribution with degrees of freedom is approximated by the Satterthwaite approximation as follows.
In Dong, et al. [9], the number of reference lots in is only adjusted for the weight of the reference variance estimator but not for the variance itself. Following the same logic, we compute the Adjusted MWCMLE for imbalanced sample (AMWCMLE).
With the adjustment, AMWCMLE can be severely smaller than the corresponding MWCMLE when the ratio of the numbers of the lots for both products is extremely large. Thus, the adjusted type I error rate and power can be severely smaller than the unadjusted type I error rate and power. We evaluate the adjusted type I error rate and power in Section 3 as well.
We first describe five simulation scenarios and corresponding simulation setups and then show simulation results of type I error rate and power performance of three Wald tests: MWCMLE, UMWCMLE and CMLE-method.
We consider four scenarios to present the performance of the proposed MWCMLE in terms of type I error control and power improvement. Chen, et al. [3] demonstrated through simulation study that the Wald type tests were monotone tests, so that power increased with for testing and with for testing . With the monotone property, the type I error rate simulated at the boundary of and is the maximum type I error rates of the two one-sided tests. The four scenarios are described below.
Scenario 1: Show power function for the MWCMLE is monotone.
Scenario 2: Compare type I error rate and power of the MWCMLE to type I error rates and powers of the CMLE-method and the UMWCMLE with equal and unequal numbers of test and reference lots and different variance ratios of test product to reference product.
Scenario 3: Compare type I error rate and power of the MWCMLE to type I error rate and power of the AMWCMLE for unequal samples with different variance ratios.
Scenario 4: Generate type I error rate and power of the MWCMLE for small number of equal product lots with different variance ratios.
In Scenario 4, the simulated power for the MWCMLE is less than 85% with the number of product lots being ten and equal product variability. To satisfy the criteria that the power is greater than 85% with the number of product lots being ten and equal product variability, we increase the margin f from 1.5 to 1.7. Accordingly, the hypotheses are changed to
Then, we repeat the process in Scenario 4 and denoted this scenario as Scenario 5.
We conduct extensive simulation studies to evaluate the MWCMLE by using type I error rate and power performance. The simulation setups for each scenario are described as follows.
Scenario 1: Let and let from -2.0 to 2.0 by 0.1. Various allocations of the number of product lots are considered. When the numbers of product lots are equal , the following number of test lots is used: . When the numbers of product lots are not equal, the following numbers of product lots are used: (10, 6) and (6, 10). Then, are generated independently from Normal and from Normal , respectively.
Scenario 2: To compare with the simulation results of the CMLE-method in Chen, et al. [3], the same simulation setups as described in their study are used. The following configurations are used: . The Effect Size (ES) is set at 1.5 and 0.125 for type I error rate and power, respectively. Various allocations of the number of product lots are considered. When the numbers of product lots are equal , the following number of test lots is used: where are chosen to represent from practical small sample sizes used in biosimilar and large sample size to show the convergence to normal approximation test. When the numbers of product lots are not equal, the following numbers of product lots are used: = (10, 6), (10, 25), (10, 100), (6, 10), (25, 10), and (100, 10). and are generated independently from Normal and from Normal , respectively.
Scenario 3: Same simulation setups as Scenario 2 are used.
Scenario 4 (f = 1.5) and Scenario 5 (f = 1.7): The following configurations are used: from 0.5 to 2 by 0.25. . ES isset at 1.5 or 1.7 and 0.125 for type I error rate and power, respectively. We only consider the case when the numbers of product lots are equal from 10 to 15 by 1. Then, and are generated independently from Normal and from Normal , respectively.
Throughout the simulations, we fix the test significance level at for each one-sided hypothesis test. The results are based on one million independent replicates for each simulation setup so that the standard error of simulation can be around .
Figure 1 shows the plots of the simulated power values against the effect size values for testing the null hypotheses in (1). First, as we can see, when the numbers of lots increase, the simulated power increases. Secondly, when the effect size is from -2.0 to zero or from 2.0 to zero, the simulated power increases monotonically. Thus, MWCMLE has the monotone property, and the Wald tests can be performed at the boundary of the null hypotheses .
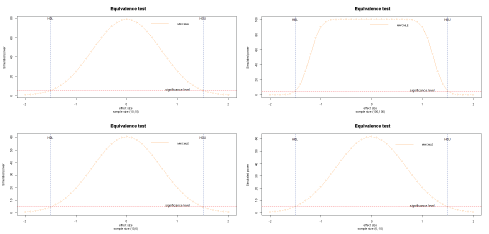 Figure 1: Power function for the MWCMLE when the effect size is from -2.0 to 2.0. View Figure 1
Figure 1: Power function for the MWCMLE when the effect size is from -2.0 to 2.0. View Figure 1
Table 1 shows the simulated type I error rates for three methods at different combination of the variance ratio of test product to reference product and equal numbers of product lots. The simulated type I error rate of MWCMLE is below the nominal significance level except for some scenarios when the numbers of product lots are six. Compared to the results for the MWCMLE, the simulated type I error rate for the CMLE-method is more conservative and the simulated type I error rate for the UMWCMLE is more liberal and inflated. Common patterns for all three methods are observed. First, when the numbers of lots increase, the simulated type I error rate converges to the significance level . Secondly, when the numbers of product lots are six and the variance ratio is large , the simulated type I error rate is less than 4.3%. When comparing three methods, the simulated type I error rates from high to low are the UMWCMLE, the MWCMLE, and the CMLE-method, respectively.
Table 1: Simulated type I error rates (%) for three Wald Tests with different variance ratios when the numbers of product lots are equal if f = 1.5. View Table 1
Table 2 shows the simulated type I error rates for three methods at different combination of the variance ratio and unequal numbers of product lots. The simulated type I error rate of MWCMLE is below the nominal significance level, except that the numbers of product lots are as follows: = (10, 25), (10, 100), or (6, 10). Compared to the results for the MWCMLE, the simulated type I error rate for the CMLE-method is more conservative and the simulated type I error rate for the UMWCMLE is more liberal and inflated. The CMLE-method and the MWCMLE share the following common patterns. First, when the number of reference lots increases, the simulated type I error rate increases at each level of the variance ratio. When the number of test lots increases, the simulated type I error rate decreases at each level of the variance ratio, except the large variance ratio . Secondly, the simulated type I error rate is less than 4.3% when the variance ratio is large and the numbers of product lots are as follows: = (10, 6) or (6, 10). When comparing three methods, the simulated type I error rates from high to low are the UMWCMLE, the MWCMLE, and the CMLE-method, respectively.
Table 2: Simulated type I error rates (%) for three Wald Tests with different variance ratios when the numbers of product lots are unequal if f = 1.5. View Table 2
Table 3 shows the simulated power for three methods at different combination of the variance ratio and equal numbers of product lots. For all three methods, when the numbers of lots increase, the simulated power increases. When comparing three methods, the simulated powers from high to low are the UMWCMLE, the MWCMLE, and the CMLE-method, respectively.
Table 3: Simulated power (%) for three Wald Tests with different variance ratios when the numbers of product lots are equal if f = 1.5 and . View Table 3
Table 4 shows the simulated power for three methods at different combination of the variance ratio and unequal numbers of product lots. For all three methods, when the number of reference lots increases or the number of test lots increases, the simulated power increases. When comparing three methods, the simulated powers from high to low are the UMWCMLE, the MWCMLE, and the CMLE-method, respectively.
Table 4: Simulated power (%) for three Wald Tests with different variance ratios when the numbers of product lots are unequal if f = 1.5 and . View Table 4
Table 5 compare the simulated type I error rate and power of the MWCMLE to the simulated type I error rate and power of the AMWCMLE with different variance ratios and unequal numbers of product lots. As we expected, the simulated type I error rate and power of the MWCMLE decrease after adjusting the degree of freedom at each level of the variance ratio. In addition, when the ratio of the numbers of the lots for both products is 10, the adjusted type I error rate and power can be severely smaller than the unadjusted type I error rate and power.
Table 5: Simulated type I error rates (%) and power (%) for MWCMLE and AMWCMLE with different variance ratios when the numbers of product lots are unequal if f = 1.5 and (for power only). View Table 5
Supplementary Table 1 and Supplementary Table 2 in the Appendix 3 show that the simulated type I error rate and power of the MWCMLE for small equal numbers of product lots with different variance ratios and f is 1.5. The MWCMLE can control the simulated type I error rate well in this specified range of the number of lots and the variance ratios. In addition, the simulated power increases when the numbers of lots product increase; the simulated power decreases when the variance ratio increases.
Similarly, Supplementary Tables 3 and Supplementary Table 4 in the Appendix 3 show that the simulated type I error rate and power of the MWCMLE for small equal numbers of product lots with different variance ratios and f is 1.7. The MWCMLE can control the simulated type I error rate well in this specified range of the number of lots and the variance ratios. In addition, the simulated power increases when the numbers of product lots increase, the simulated power decreases when the variance ratio increases. Compared to the simulated power in Supplementary Table A.2 when f is 1.5, the simulated power in Supplementary Table A.4 when f is 1.7 is larger for each combination of the number of lots and the variance ratios.
To illustrate the application of the proposed MWCMLE, we provide an example in this section. We use the same simulated CQA data in Dong, et al. [2] to present the results for the current practice [1] and the proposed MWCMLE. The numbers of product lots are ten. Each individual observation of the test product is 94, 109, 103, 97, 102, 101, 99, 97, 97, and 103; each individual observation of the reference product is 96, 104, 102, 102, 101, 99, 99, 92, 107, and 98. Then, the sample means for the test product and the reference product are 100.2 and 100.0, respectively. In addition, the sample variances for the test product and the reference product are 18.6 and 17.8, respectively. Furthermore, by using the proposed MWCMLE, the overall null hypothesis is rejected by either of the following two criteria: first or second, the 90% confidence interval falls within the equivalence margin . The 90% confidence interval is derived by converting the above first criterion as follows.
Thus, the 90% confidence interval for the proposed MWCMLE derived from the two one-sided tests is as follows.
The code is provided in the Appendix 2. Then, the following results are calculated. When f is 1.5 and the equivalence margin is (-6.32, 6.32) in the current practice, the 90% C.I. is (-3.11, 3.51), when f is 1.7 and the equivalence margin is (-7.17, 7.17) in the proposed MWCMLE, the 90% C.I. is (-3.83, 4.23). Thus, the data can pass the equivalence test by using both methods.
We develop asymptotic tests using the Wald test statistic, for parallel-arm variance-adjusted equivalence trials with normal endpoints. Our results of the MWCMLE show that either the type I error rate controls closely below to the nominal level when the numbers of product lots are equal and greater than or equal to ten or the type I error rate can be inflated to around 5.2% when the numbers of product lots are unequal. In addition, the simulated type I error rate of the CMLE-method is more conservative than the one of the MWCMLE; the simulated type I error rate of the UMWCMLE is more liberal and inflated than the one of the MWCMLE.
In terms of power for three methods, our results show that the UMWCMLE outperforms the other two methods, especially when the numbers of product lots are small. However, as shown in our simulation, the simulated type I error rate of the UMWCMLE is inflated, indicating higher false positive rate. Thus, the UMWCMLE is not a proper estimator choice. In contrast, when the numbers of product lots are increasing, the simulated power of the MWCMLE improves and outperforms the CMLE-method. Thus, the MWCMLE can be a proper choice among these three methods.
Since the equivalence margin is unknown and estimated from the reference data, the simulated power of the MWCMLE is less than 85% with the number of product lots being ten and equal product variability when f is 1.5. To satisfy the criteria that the power is greater than 85% with the number of product lots being ten and equal product variability, f needs to be increased from 1.5 to 1.7 as shown in (3).
In conclusion, using the Wald test for equivalence testing of the hypothesis setting in (1) can be conservative when the numbers of product lots are small. However, using CMLE for the variance estimation can improve the performance of Wald Test as shown in Chen, et al. [3]. Our investigation of MWCMLE and UMWCMLE show that the proposed MWCMLE can control the type I error rate well and increase the power over CMLE-method while the type I error rate of the UMWCMLE can be over liberal and inflated. Further detailed comparisons with other methods will be reported in a different paper.